Bonjour
je tente de lancer un job sur bigmem sans succès.
Il est placé en pending status depuis plusieurs jours alors qu'il semblerait que les ressources sur bigmem soient disponibles.
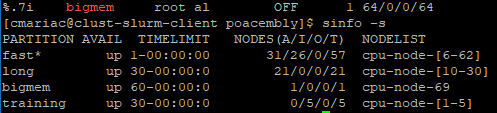
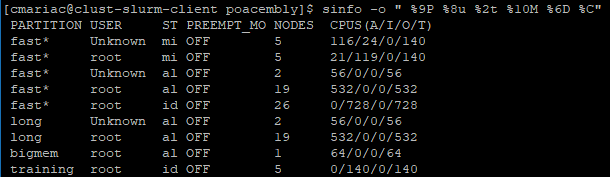
La partition bigmem utilise le node cpu-node-69, est il possible que ce noeud soit actuellement utilisé par une autre partition ?
Pourriez vous valider mon script ci dessous.
MERCI !
Cordialement
Cédric MARIAC
#!/bin/bash
#SBATCH -N 1 # nombre de nœuds #SBATCH -n 4 # nombre de cœurs #SBATCH --mem 1000GB # mémoire vive pour l'ensemble des cœurs #SBATCH -t 8-00:00 # durée maximum du travail (D-HH:MM) #SBATCH -o slurm.%N.%j.out # STDOUT #SBATCH -e slurm.%N.%j.err # STDERR #SBATCH --partition bigmem
Merci Julien,
Ceci explique pourquoi tous les noeuds de la partition bigmem soient actuellement réservés par les partition Fast ou Long.
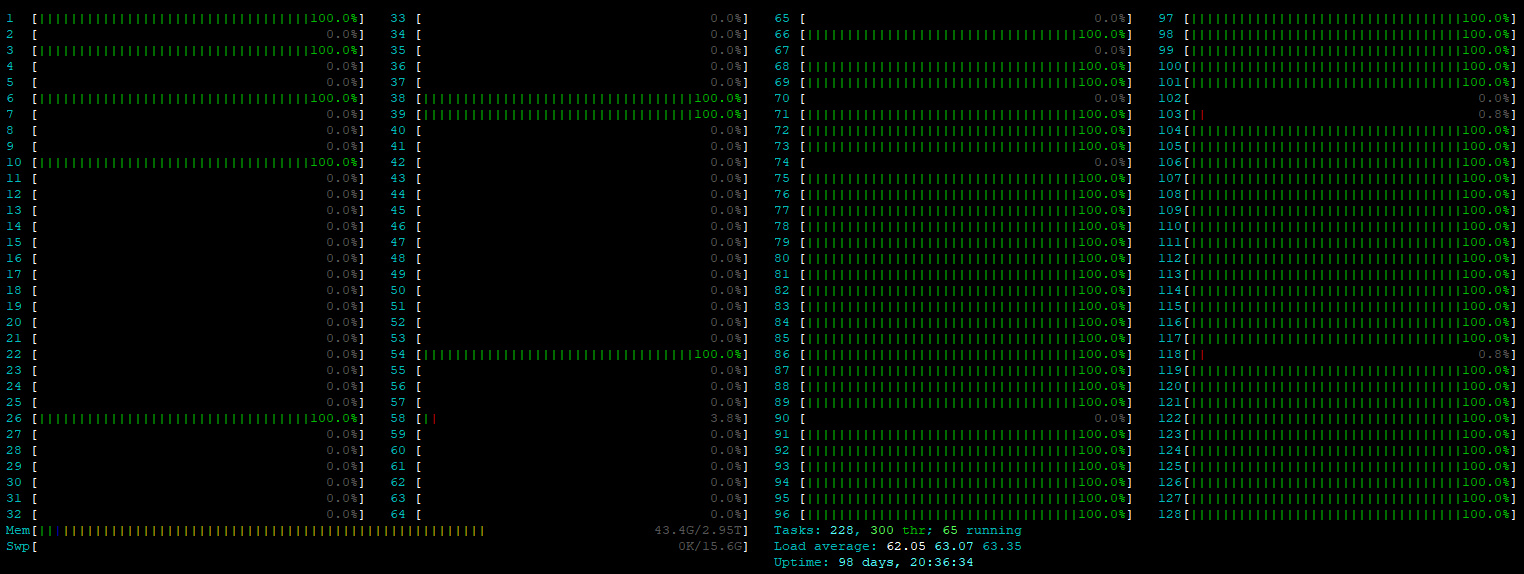
Cependant il me semble que sur cpu-node-69 un certain nombre de noeuds qui "travaillent" pas sont inaccessibles.
Est il possible qu'ils aient été réservés lors d'un lancement de job (-n 64) sans pour autant qu'ils soient nécessaires ou utilisables mais du coup soient inaccessibles aux autres utilisateurs ?
Le noeud 69 dispose en tout de 64 coeurs (128 threads) et 3To de RAM.
Il y a actuellement 64 jobs en cours sur ce noeud réservant chacun 1 coeur. La réservation est valable que le coeur soit effectivement en utilisation en pleine charge ou non.
Tant que ces jobs ne sont pas terminés où qu'ils n'ont pas atteint de la walltime de 30 jours, les ressources ne seront pas libérées.
De retour sur le cluster après qq mois d'absence, j'essaie de lancer un sbatch sur la nouvelle partition bigmem mais j'ai une erreur que je n'arrive pas à résoudre.
Y a t'il maintenant une politique d'accounting ou bien est ce que j'ai une erreur dans mon script?
Est ce qu'un admin peut jeter un oeil sur mon script /shared/projects/phycovir/JGI/SPADES.SLURM pour voir ce qui cloche ?
Pour éviter de saturer inutilement la partition bigmem et en attendant un système plus flexible, il est maintenant nécessaire de demander l'accès à bigmem.
Je viens de vous autoriser l'accès. Votre script/job doit pouvoir être à nouveau lancé.
je rencontre un nouveau probleme pour lancer un job sur bigmem qui est pourtant libre actuellement:
sinfo -p bigmem
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
bigmem up 60-00:00:0 1 idle cpu-node-69
Une fois lancé via sbatch, le script ne se lance pas:
squeue -p bigmem
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
14150233 bigmem MMSEQS69 gblanc PD 0:00 1 (ReqNodeNotAvail, UnavailableNodes:cpu-node-[6-12,15,20,22-26,72-73])
Pourtant ma réservation semble correcte (et a déjà fonctionné comme telle):
En prévision de notre coupure du 16 et 17 décembre prochain, une réservation a été placée sur l'ensemble des noeuds de calcul du cluster. Il est ainsi impossible de lancer un job qui risque d'empiéter sur la période de coupure.
En lançant un job sur la partition bigmem sans préciser de limite de temps, le job est supposé pouvoir tourner pendant la durée maximum autorisée de la partition, soit 60 jours. Il est donc actuellement refusé par le cluster.
Afin de pouvoir lancer votre job, vous devez spécifier une limite de temps inférieur à 13 jours en ajoutant par exemple l'option :