Bonjour M. Benaben,
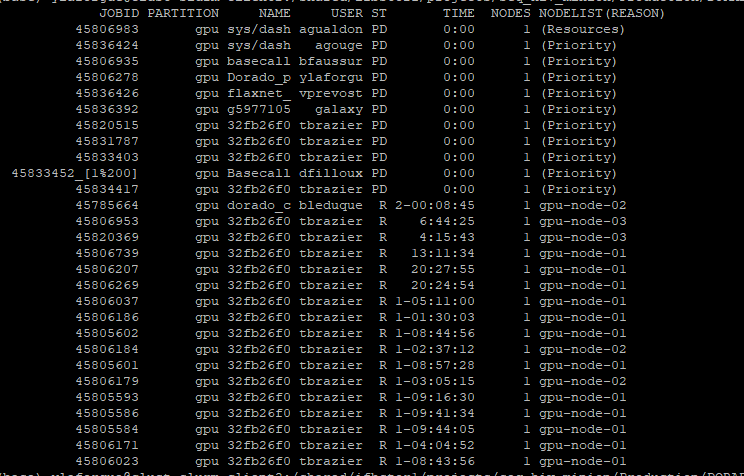
Je me permets de vous poser une question concernant l’utilisation du cluster : est-il normal qu’un utilisateur soit réparti sur trois nœuds différents simultanément ?
Il y a pas de règle spécifique pour lancer les jobs un par un ?
Est-ce peut-être un utilisateur disposant d’un compte prioritaire ou payant ?
Je cherche simplement à mieux comprendre le fonctionnement du cluster afin d’optimiser mes propres lancements de jobs.
Bonne journée
1 « J'aime »
Bonjour,
On peut lancer autant de jobs que l'on souhaite (enfin la limite est à pls milliers).
Les limites sont sur le nombre de CPU et RAM utilisés simultanément (jobs "running") par utilisateur (https://ifb-elixirfr.gitlab.io/cluster/doc/slurm/slurm_at/#the-partitions-and-resource-limits).
Il n'y a pas de compte prioritaire ("VIP") si ce n'est les jobs lancés via Galaxy qui ont une priorité plus importante.
Slurm affecte par contre une priorité aux jobs sur plusieurs paramètres: temps passé dans la file d'attente, ressources déjà consommées par le compte, la taille du job, etc. (cf Slurm Workload Manager - Multifactor Priority Plugin).
Mais dans tous les cas, lorsque les ressources sont disponibles, les jobs sont lancés (dans la limite par utilisateur explicité plus haut).
C'est ce qui c'est passé avec les jobs de l'utilisateur (gpu dispo, pas d'autre demandes, dans la limite CPU/RAM accepté −> jobs exécutés).
Du coup, les jobs lancés peu après sont en attente.
Malheureusement, c'est quelque chose de compliqué à gérer.
Les GPU peuvent être inutilisé pendant plusieurs jours et tout d'un coup, il y a X demandes simultanés.
D'autant qu'i y a peu de ressources, donc peu de marge de manœuvres.
On va quand même regarder pour éviter la monopolisation de tous les GPU par un seul utilisateur.
PS: puis-je mettre notre échange en publique (ie visible par tous), je suis sûr que votre question intéresse d'autre personne ?
Oui, aucun problème, vous pouvez partager notre échange sur la communauté publique.
Merci pour votre réponse très détaillée, qui permettra à chacun de mieux comprendre le fonctionnement du cluster.
Bonne journée à vous.
Merci pour votre retour. Le sujet est passé public.
@amoreau Nous avons mis un nouveau paramétrage en place pour limiter le nombre de GPU à 2 par utilisateur (maxTRESPerUser=gres/gpu=2).
2 « J'aime »